
Understanding Generative Adverserial Networks - Part 1
This is a two part series on understanding Generative Adversarial Networks (GANs). This part deals with the conceptual understanding of GANs. In the second part we will try to understand the mathematics behind GANs.
"Generative Adversarial Networks is the most interesting idea in the last ten years in Machine Learning." - Yann LeCun
First, we’ll dissect the name GAN for a slightly better understanding.
Generative: The technical definition is this:
A generative model is a statistical model on the joint distribution of X and y. This can be abstractly represented by: P(X, y) where X is the input and y is the target.
Adversarial: This is basically anything that involves conflict, and thus this word fits perfectly in this context.
Network: This of course refers to the fact that this model comprises of two neural networks, each consisting of several hidden layers.
The two main components of a GAN are the generator and the discriminator. The technical definition of a discriminative model is mentioned below.
Discriminative: This a statistical model which gives a conditional probability of a target y given when given a particular input x from a distribution X, that is: P(y | X = x).
What this basically means is that when the discriminator is given something as an input, it outputs the chance of that particular input being real. 1 means that it’s confidently real while 0 means that the discriminator is completely sure it’s fake.
We’ll now discuss the underlying concept behind GANs with an example. The generator is akin to a currency forger, while the discriminator is like a police officer.
When training of a GAN starts, the ‘forger’ is new to the job and the ‘officer’ (the discriminator) can easily distinguish between authentic and counterfeit currency. The officer also tells the forger what the difference between the two money samples was. Based on this, the forger tries to improve his method of generating fake currency.
This process continues, with the officer (discriminator) getting better at telling fake money from authentic money and the forger (generator) getting better at fooling the officer.
Ultimately, a time comes when the chance of guessing (the officer can no longer confidently spot a difference) the fake from the real is exactly 0.5 -- a random guess. After training, any money the forger creates is exactly like real currency. This is the end goal of training a GAN. Consider the graphs below:
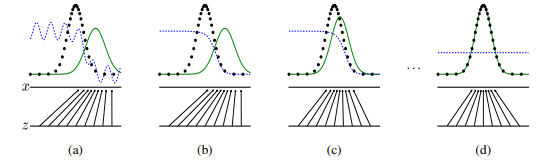
The dotted distribution is the real money (input data), represented by pdata.
The green distribution represents the money generated by the forger (generated data), represented by pg.
Finally, the dotted purple curve is the officer’s guess of how real the currency is, represented by pd. Likewise, the noise distribution, from which the generator gets input is represented by pz.
Studying the pd curve in the graphs, you can intuitively tell from (a) that the chance of the data being real is very high near pdataas its represents real money. It goes down near pgas the discriminator knows the data is fake or generated.
As we progress through the training, we notice the green distribution (pg) getting closer to the black distribution (pdata).
Ultimately, they coincide, and the discriminator has a 50% chance of guessing correctly. Notice how the purple dotted line (pd) is constant halfway through the curve.
D(G(z)) = 0.5
In a broad sense, DG*(x), the ideal value of D(G(z)), when z = x , can be represented as shown below:
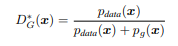
In figure (d), when both the pg and pdata distributions coincide, we can say that: pg = pdata
Hence, DG*(x) = pdata2 Pdata = 0.5
The input to the discriminator can be a real image or a fake (generated) image. The generator is passed noise of some distribution like gaussian or even uniform. The generator generates random images that look like the real data from this noise. The discriminator outputs the probability of that input being real.
The generator and discriminator play what is known as a Minimax game in Game theory. The goal of one player is to minimize the final ‘score’ of the game, called the “minimizer”. The goal of the “maximizer” is to maximize the possible score, given that both players play optimally. The Minimax Algorithm is often used in two player games like tic tac toe and chess.
Here, the discriminator is the ‘maximizer’ and is trying to maximize the chance of it guessing correctly. By correctly, what I mean is that it should correctly label an image from the input dataset as a real image and a generated image as a fake one . The generator, on the other hand, is trying to make the discriminator incorrectly guess the generated images as real images.
I feel strongly that unless you understand a concept that is largely based on mathematics, to the last variable, its very difficult to build on that concept. We will cover the mathematical aspect of GANs in the next part.
References: https://arxiv.org/pdf/1406.2661.pdf
By:
Aniruddha Karajgi
Research Intern,
Cere Labs



Generative Adversarial Networks (GANs) are an advanced technique in Machine Learning used to generate new data that resembles real-world data. Introduced by Ian Goodfellow, GANs consist of two neural networks—the generator and the discriminator—that compete with each other in a game-like process. The generator creates fake data (such as images), while the discriminator evaluates whether the data is real or fake. Over time, this competition improves both networks, resulting in highly realistic outputs.
ReplyDeleteThe generator learns to produce data that closely mimics the training dataset, while the discriminator becomes better at detecting subtle differences. This adversarial training process continues until the generated data becomes almost indistinguishable from real data. GANs (Generative AI Projects for Final Year) are widely used in applications such as image generation, video creation, data augmentation, and even deepfake technology. Despite their power, GANs can be challenging to train due to issues like instability and mode collapse. Overall, GANs represent a significant breakthrough in generative modeling, enabling machines to create realistic and high-quality synthetic data.
ReplyDelete